Parser与Tokenizer实战:解密一段“诡异”的Python代码
有位老哥(@nedbat)在 Twitter 上发布了这么一条状态,引起了我的好奇:
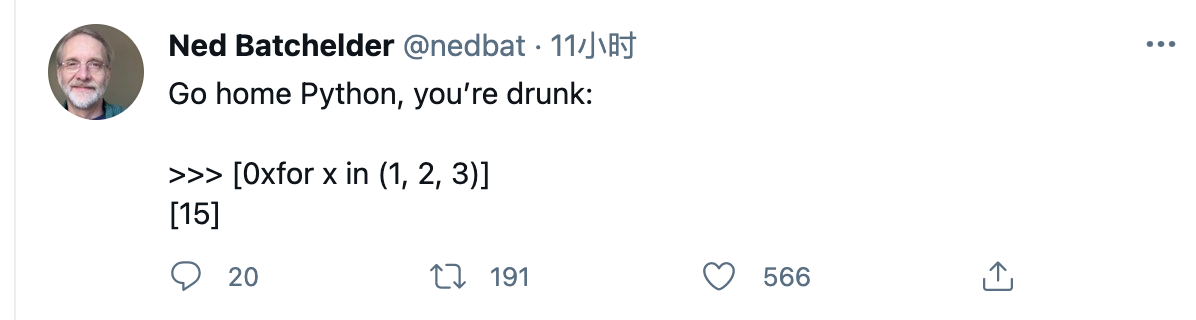
也许很多人会同样好奇:
- 不应该是一条语法/词法错误么?
- 为什么会是 15 ?
实际上,回答问题2比问题1容易得多。考虑到这是一个 list comprehension 语句,我们很容易猜想:元组的内容是否会影响结果?
>>> [0xfor x in (1,2,3,4)]
[15]
>>> [0xfor y in (1)]
[15]
>>> [0xfor x in ()]
[15]
>>>
显然,元组中的内容以及循环变量都不会影响答案。此时我们注意到 0xfor 与十六进制整形字面量非常相似,同时联想到:
15 == 0xf == '[0xf]or'
也就是说,至少 0xfor 的前三个字符被解释为了十六进制整形字面量,进而形成了最后的答案 [15]。我们可以使用 tokenizer 包来验证这个猜想:
# file buggy-python-listcomp.py
[0xfor x in (1, 2, 3)]
# $ python -m tokenize buggy-python-listcomp.py
1,0-1,1: OP '['
1,1-1,4: NUMBER '0xf'
1,4-1,6: NAME 'or'
1,7-1,8: NAME 'x'
……
为什么不是一条语法错误?
我们可以借助 astpretty 来审查该语句的 AST。astpretty 包是对 Python 标准库 ast.parse 的一个封装,前者输出的语法树更加美观易读。考虑到这实际上是一个语法范畴的问题,因此我们有意将元组替换为了空元组:
>>> import ast
>>> import astpretty
>>> astpretty.pprint(ast.parse('[0xfor x in ()]').body[0])
Expr(
# 省略了部分不必要内容
value=List(
# ……
elts=[
BoolOp(
# ……
op=Or(),
values=[
Constant(lineno=1, col_offset=1, end_lineno=1, end_col_offset=4, value=15, kind=None),
Compare(
#……
left=Name(lineno=1, col_offset=7, end_lineno=1, end_col_offset=8, id='x', ctx=Load()),
ops=[In()],
comparators=[Tuple(lineno=1, col_offset=12, end_lineno=1, end_col_offset=14, elts=[], ctx=Load())],
),
],
),
],
ctx=Load(),
),
)
通过输出的 AST,我们很容易地发现了问题的症结:
0xfor被解释成了0xf以及or- 进而 list comprehension 被解释成了一段布尔表达式,后面的
x in ()是待求值的表达式 - 由于
or短路运算的特性,由于0xf被解释为真,因此后面的x in ()将不会被求值,进而不会产生语法错误
那么,为什么不是一个词法错误?
读者一定会质疑,为什么是把 0xfor 解释成了两个 token ,而不是一个词法错误?毕竟,o 和 r 都不是有效的十六进制字面量。让我们看看 Python 的 tokenizer 是如何处理的,谜题就不言自明了。
/* Number */
if (isdigit(c)) {
if (c == '0') {
/* Hex, octal or binary -- maybe. */
c = tok_nextc(tok);
if (c == 'x' || c == 'X') {
/* Hex */
c = tok_nextc(tok);
do {
if (c == '_') {
c = tok_nextc(tok);
}
if (!isxdigit(c)) {
tok_backup(tok, c);
return syntaxerror(tok, "invalid hexadecimal literal");
}
do {
c = tok_nextc(tok);
} while (isxdigit(c));
} while (c == '_');
}
当 tokenizer 扫描到前导的 0x 或 0X 字符,则会尝试读入十六进制字面量。并且要求紧跟的第一个字符必须是有效的十六进制数字符(isxdigit());对于之后的字符,如果不是十六进制字面量,则认为是新的记号,进而认为目前识别了一个完整的记号。
如果单从字符上就能区别两种/两个不同的记号,那么不需要再使用空格来分隔,Python 在官方文档中提到了这样的策略,详见 Whitespace between tokens。虽然这种策略也会让 tokenizer 实现起来稍微简单的一点,但是你真要这么做的话,Wat。
More fun
一旦接受了这个设定,还是可以创造出一些好玩的片段。下面就是 Twitter 原文中网友们的跟帖:
# @howtodowltle
>>> [0x1decade or more]
[31378142]
# @valkoder
>>> [0xdeadbefor alive]
[233495535]
然而我个人最喜欢下面这个:
# @fredly
>>> 0xfor-d*University
Happy Coding, have fun~