RbStreem: streem语言的玩具级实现,或,面向管道编程的研究
作为一名 Ruby 脑残粉,我在大概三年前(2013年)的样子把 Matz 的两本技术合集《松本行弘的程序世界》和《代码的未来》给读完了。Matz 本身对分布式和高并发有着浓厚的兴趣,特别是从《代码的未来》这本书里面可以发现,Matz 对 UNIX Shell 的管道钟爱有加,他认为使用管道来实现高并发有着相当大的前途,于是着手设计了 streem语言 。但是在相同的时间段,我读了三本书,让我重新思考了关于 streem 语言的一些问题。
首先是 Communication Sequential Processes 一书,该书是 Hoare 爵士写的,在80年代左右由他的好友中科院周巢尘院士译成了中文——《顺序通信进程》。书里面提出了一种叫做 CSP 的语言,用来描述并发性系统间进行交互的模式。CSP 本身就是基于 Channel 的(在逻辑上,Channel 和管道是相同的概念),在 CSP 模型中,Process 之间互不通有无,而只是向关联的 Channel 中发消息,由 Channel 再向 Process 中发消息。
接着是《深入理解 Linux 内核》一书,该书的第十九章详细地介绍了 Linux 管道的实现方式。该书指出,管道(Pipe)被看做是一个打开的文件,但是在已安装的文件系统中没有相应的映像。可以使用 pipe() 系统调用来创建一个新管道,该系统调用放回一对文件描述符;然后进程通过 fork() 把这两个描述符传递给它的子进程,由此与子进程共享管道。
然后是《计算机程序的构造和解释》一书,该书在3.3.5小节里面讲了一个“约束传播”网络,非常有意思,并且也是促使我实现 RbStreem。在约束传播网络中,我们首先要构建约束关系。约束传播网络可以看做 (V, E) 图,其中,点 V 被称为“约束”,可以分为:①特定的约束关系,比如约束 (multiplier x y z) 就描述约束关系 xy = z;②常量约束关系,比如约束 (const 3.14 x) 就表示 x 的值永远都是 3.14。而图的边 E 可以看做约束的电路连线,术语叫做连接器,链接器是一种对象,它们可以“保存”一个值,使之能够参与一个或多个约束。约束网络始终趋于保持约束平衡,一旦网络中某个部分的值发生改变,与它相关约束的其它约束量将会被重新计算,并通过连接器向其它的约束传播,从而使整个网络达到新的平衡。这个系统最强大的地方,一个在于它是用一组约束方程来描述系统状态,是一种声明式编程的方法;二来在于它实现的是双向数据流传播,这种思想非常惊艳。
SICP 书里面,Abelson 和 Sussman 教授一再给我们强调在语言中构建语言——也就是元编程的强大威力,因为你所构建 DSL 语言可以自动继承宿主语言的强大能力。我在考察了 streem 语言的语法后,认为通过牺牲一些比较“花哨”的语法(Semantics over syntax!),完全可以采用 Ruby 的语法来表达 streem 语句。因此,我决定试着在 Ruby 语言的层次上实现 streem 。这也是为什么我把这个项目叫做 streem.rb 或者 RbStreem 。
这个小系统看起来很简单,但在实际上手的时候,我在设计的选择上遇到了很多纠结的地方,这也是为什么我把这个小玩具搁置了两年。现在,我就利用这个机会,向大家介绍一下我在设计与实现 RbStreem 时候的一些思考。
演示
先上代码和演示效果!
cat (example/01cat.strm.rb)
- 代码
# most fundamental Streem program
# build pipeline from STDIN to STDOUT
STDIN.| STDOUT
# actual stream processing will happen in the event loop
# that starts after all program execution.
- 连线图
- 运行效果
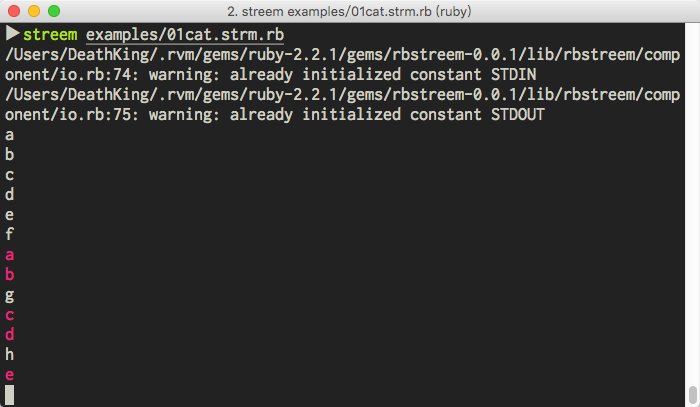
注意,这里为了区分输入和输出,我修改了一下源码。运行效果中白色的字符串是标准输入,而红色的字符串是标准输出。
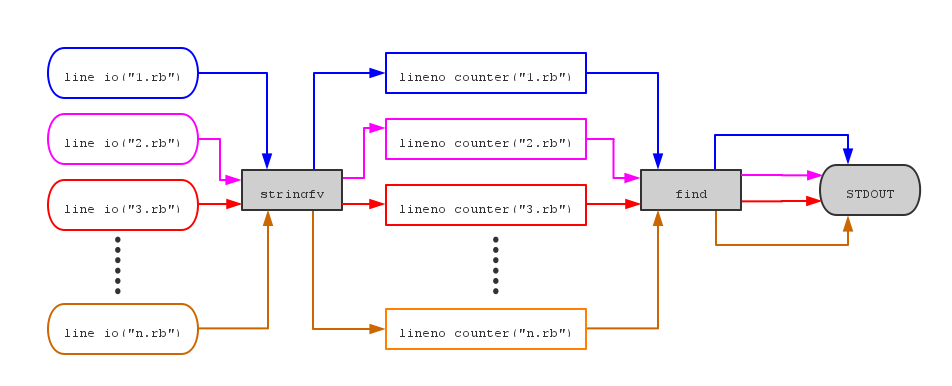
grep (example/11grep.strm.rb)
这个例子演示的是 RbStreem 脚本在搜索一个特定目录下所有的 Ruby 脚本文件是否包含某个特别的字符。如果找到,则输出该行,并加亮该字符串。这个代码是原 streem 范例中没有的演示代码,不过本例也能演示出 RbStreem 中比较有意思的地方。
- 代码
def lineno_counter(filename)
lineno = 0
Component(-> str do
lineno += 1
"[#{filename}:#{lineno}] #{str}"
end)
end
def find(pattern, color)
Component(-> str do
if str.gsub!(pattern) {|match| match.send(color)}
str
else
skip
end
end)
end
cached = {chomps: chomps, find: find(strm_arg[0], :red)}
Dir.glob("./**/*.rb") do |filename|
line_io(filename).
| cached[:chomps].
| lineno_counter(filename).
| cached[:find].
| STDOUT
end
- 连线图
- 运行效果
Agent:运算实体
首先要介绍 RbStreem 的一些基本概念。第一个是 Agent ,Agent 是一个运算实体,表征一个具体的运算。
在目前的版本中,只要实现了 call、producer?、ready?、dead? 这四个方法的对象,都可以看做 Agent 。但是常用的 Agent 还是 Proc 或 lambda 对象(lambda 是一种特殊的 Proc 对象)。Agent 要求实现的四个方法的意义与解释如下:
call是一个一元函数,Component 被调度时,会从可用 Pipe 中取得一个数据,作为参数调用与之关联的 Agent 的call方法来实际执行计算。producer?谓词用于向系统说明该 Agent 是否一定需要一个参数来执行call方法。有一些计算并不依赖于输入,每次对其调度即可产生一个值,例如虽然 lambda 表达式-> _ { 3 }需要一个参数,但它的产生的计算结果是一个常值,因此无需等待输入 Pipe 的数据就绪。但是如果producer?谓词求值为false,这就意味着,Component 需要输入管道有可用数据时,才能触发与之关联 Agent 的call方法。ready?谓词用于返回 Agent 是否已就绪,从而可以调用call方法。dead?谓词用于判断 Agent 是否已经停机,从而可以从系统中移除。
Component:Agent的运行实体
第二个要明确的概念是 Component 。Component 根据一个 Agent 进行初始化,可以认为 Component 是 Agent 的一个封装。
Agent 描述了“需要执行什么样的计算”,而 Component 则描述了“计算所需资源如何取得”以及“计算结果放至何处”。这是因为 Component 可以通过 Pipe 与其它 Component 相连,并通过该 Pipe 进行单向数据通信。一个 Component 可以有多个输入和输出 Pipe 。
从这个角度来说,Component 更像操作系统中的“进程”,与其关联的输入、输出 Pipe 可以类比为进程所打开的文件描述符。而 Agent 更像是一个“程序”,或者说一个“算法”。或者可以认为 Component 是一个动态的观点,而 Agent 是一个静态的观点(由于我们是直接在 Ruby 之上构建的 RbStreem ,因此 Agent 不单依靠 Component 获得资源,其本身也可以通过其它途径获得资源,因此我们需要指出的是这种看法并不是绝对的)。
虽然说 Component 更像是一个“进程”,但 RbStreem 并没有限制 Component 的实现方式,并且我现在也有意尝试提供 Component 的不同实现,以提供更灵活的调度。另外,类比存在于进程之中的线程,Component 内部是否需要更细粒度的调度单位,这也是 RbStreem 思考的一个问题。与 Agent 类似,RbStreem 要求 Component 实现ready?、blocked?、dead? 三个谓词来描述运行状态,用以辅助调度。目前版本是按照操作系统设计的思路来实现的,目前看来或许过于冗余,在未来的版本中,Component 和 Agent 可能有更精简的状态谓词。对这三个有关状态的谓词,解释如下:
ready?谓词用于描述 Component 是否已就绪,如果 Component 的状态为ready,那么它将有机会被调度器选中,并执行其run方法。其判断算法可以描述为:- 如果关联的 Agent 没有就绪,那么该 Component 必然不会就绪。
- 如果该 Component 没有跟任何输入 Pipe 但是关联的 Agent 是一个
producer。那么这就意味着我们不需要任何来自于输入 Pipe 的数据,故该 Component 就绪。 - 否则的话看输入 Pipe 中是否有可用数据。
blocked?谓词在目前的版本中并没有实际的用途,只是一种对操作系统中进程状态设计的模仿。dead?谓词用于描述 Component 是否已经无法再次被调度,如果调度程序发现 Component 的状态为dead,则将其移出调度队列。其判定算法可以描述为:- 如果关联的 Agent 处于
dead状态,那么该 Component 也处于dead状态。 - 如果关联的 Agent 不是
producer,并且 Component 没有与任何输入 Pipe 相连,这就意味着该 Component 没有办法获得执行 Agent 所需的资源,那么此时该 Component 也应该处于dead状态。
- 如果关联的 Agent 处于
当 Component 被调度器选中,则 run 方法被出发,该方法的运行流程如下:
- 从就绪的输入 Pipe 中随机选取一个
read_pipe。需要注意的是,由于就绪队列可能为空,因此read_pipe可能为nil。 - 如果
read_pipe不为nil,那么就获取该pipe的flow_tag。 - 如果
read_pipe不为nil,那么就从该 Pipe 中读出一个值input。 - 用调用
@agent.call(input),取得结果result。 - 如果
result不是一个SkipClass,那么就将结果广播给所有具有flow_tag标签的输出 Pipe 。如果flow_tag为nil,则广播给所有输出 Pipe 。
关于 Component 的调度(算法)问题,我们在后面的章节中会详细讨论。
Pipe:通信管道
第三个要明确的概念是 Pipe ,它是在 RbStreem 层面 Component 之间进行数据通信的唯一方式。
关于 Pipe 的连接问题
说到 Pipe 的连接问题,不得不说 Connectable 模块。Connectable 模块实现了 | 方法,如果对象所在的类引入了该模块,那么就可以使用 | 方法与其它引入了此模块的类的实例相连,| 返回一个用于表示连接情况的 Pipe 对象。由于 Ruby 中 | 是按位或操作符,不能够被对象的某一特定方法覆盖,因此我们就只能委屈求全的使用 .| 来调用 | 方法来实现对象间的连接了。在目前的设计中,只有 Pipe 和 Component 类继承了该模块,但是两个 Pipe 间相连是不合法的。理论上来说,只有 Component 之间直接相连才是合法的,但允许 Component 和 Pipe 相连,可以实现一些更复杂的情况,例如完整的数据流。考虑下面的代码:
cached = {stringfy: stringfy, seq_100: seq(100)}
cached[:seq_100].| Component(-> x {x.even? ? skip : x}).| cached[:stringfy].| red.| STDOUT
cached[:seq_100].| Component(-> y {y.odd? ? skip : y}).| cached[:stringfy].| blue.| STDOUT
如果将这段代码可视化一下,它将是像这样的流程图:
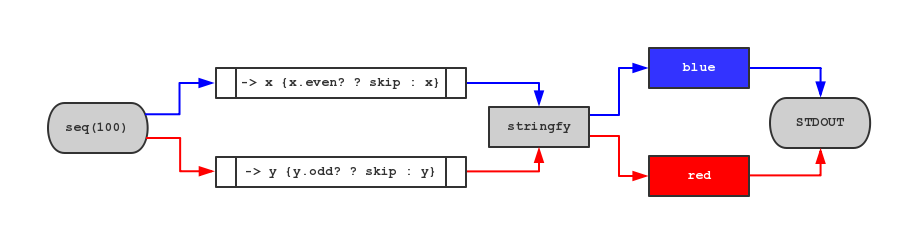
显然,整个图中有两条分离的数据流(红、蓝)。然而两条数据流又共享同一个 Component(cached[:stringfy]),因此 RbStreem 必须能够让 Component 知道,其输入来自于哪条数据流,计算结果应该送入哪条数据流。所以在实现 RbStreem 的时候,我的想法是这样的:
- 两个 Component 对象间调用调用
|方法,先为这两个 Component 新建一个用于通信的 Pipe 。并为这个 Pipe 分配一个唯一的名字和流标记(flow_tag)。名字用来唯一标识一个 Pipe ,流标记用于识别哪些 Pipe 属于同一数据流。 - 语句
a.| b.| c表示在a、b、c之间建立一条数据流,而求值过程是右结合的,也就是说,原语句等价于a.| (b.| c)。假设b、c之间建立的 Pipe 记作p,那么 RbStreem 求值语句a.| p的正确行为就应该是:①从p中取出数据源b,②将a和b用新的 Pipe 关联起来,③ 新建的 Pipe 需要继承p的flow_tag,因为这两个管道属于同一条数据流。 - Pipe 对象和 Component 对象相连,即形如
p.| a这样的调用与上一条同理。只不过需要从p中取出数据的接受者与 Component 对象a相连。 - 两条 Pipe 不能直接相连,一来是这种行为并不合理,再者,两条 Pipe 可能属于两条不同的数据流,贸然将其连接起来可能会引起混乱。
所以现在 RbStreem::Connectable#| 方法的代码实现就有点 tricky :
module RbStreem
module Connectable
def |(other)
check_connection_target_type(other)
target = other.connection_target
source = self.connection_source
flow_tag = if other.is_a? pipe
other.flow_tag
elsif self.is_a? pipe
self.flow_tag
else
Pipe.generate_flow_tag
end
Pipe.new(source, target, flow_tag)
end
end
end
Connectable 要求引入了该模块的对象必须实现 check_connection_target_type、connection_source、connection_target 三个方法。其中 check_connection_target_type 用于检测两个对象的连接是否合法(比如我们不允许两个 Pipe 对象相连)。connection_source 表示当该对象作为 | 方法的 LHS (左手方对象)时应该参与相连的对象,例如求值语句 p.| a 时,Pipe 对象 p 作为 LHS,实际参与连接的应该是 p 所的数据消费者一方,由该对象与 Component 对象 a 相连。同理,connection_target 表示当该对象作为 | 方法的 RHS (右手方对象)时应该参与相连的对象。
Pipe 的实际作用
说完了 Pipe 的连接问题,我们再来聊聊 Pipe 的实际作用。其实 Pipe 的很多工作发生在对象的实例化阶段,直接上代码:
def initialize(src, dest, flow_tag=nil)
@name = self.class.generate_pipe_name
@queue = []
@source = src
@target = dest
@flow_tag = flow_tag || self.class.generate_flow_tag
@producer.add_write_pipe(self)
@customer.add_read_pipe(self)
end
Pipe 对象本质上是对 Array 的一个封装,其内部的实例变量 @queue 作为数据队列用来暂存从 Component 传来的数据。puts 方法可以向 Pipe 中写入一个数据,反之,gets 方法可以从中读取出一个数据。Pipe 对象处于就绪状态,当且仅当其实例变量 @queue 不为空。
Pipe 类里面定义了一个叫做 broken? 的谓词比较值得玩味。Pipe 对象是否是“坏掉的”,有一下几个判定准侧:
- 如果其目标
target无效(为nil或者dead),那么 Pipe 就是坏掉的。 - 如果其目标
target一切正常,但source无效,并且内部的数据缓存@queue是空的,那么 Pipe 就是坏掉的。
Component 的运行调度
要理解 RbStreem 的调度,那么有几个细节需要交代清楚:
RbStreem::Component类里面有一个叫做@@task的实例变量,用于存放所有待调度的 Component。- 每一个
Component对象在实例化的最后一步,会把自己加入到@@task队列中。 - 不需要在 RbStreem 脚本文件中显示地请求系统开始调度。RbStreem 注册了
at_exit函数钩子,在加载完所有 RbStreem 脚本、连接关系建立完毕后,自动触发RbStreem::Component.start_schedule。 - 目前的调度算法是一个随机化算法,每次随机选出一定就绪的 Component ,让他们依次执行
run方法。 - 调度是非抢占式的,这也就意味着需要 Component 主动从运行流中退出,这样也意味着
run方法不能耗时过长,更不能陷入死循环。