静态分析中的“可靠性”指什么?
- 作 者: Michael Hicks
- 译 者: DeathKing
- 原文地址: http://www.pl-enthusiast.net/2017/10/23/what-is-soundness-in-static-analysis
译注
术语 soundy 描述了一种近似 sound 的状态,但我目前没有找到足够合适的词来对应这个概念,因此在本文中仍然保留 soundy 这个词。)**
PLUM 阅读小组最近讨论了一份发表在 USENIX Security’17 上的论文《Dr.Checker:一个针对Linux内核驱动的 soundy 分析器》。这篇论文展示了一种针对 Linux 设备驱动程序的自动化分析程序(一个静态分析器),它旨在检测一类可能造成安全问题的软件BUG。这篇论文坚称:“Dr.CHECKER”成功(它找出了一些新的BUG,其中一些被确认为漏洞)的重要原因之一是因为它的分析是 (soundy) ,而不是“可靠的(sound)”。阅读组的许多学生想知道:“这个术语指的是什么?为什么 soundy 比可靠的(sound)更好?”
为了回答这个问题,我们需要回过头来讨论一下我们在描述静态分析时用到的各种其他的术语,比如完备性(completeness)、精确度(precision)、召回率(recall)等等。这些术语的使用很混乱,从而给人们造成困惑。一次分析的值是可靠地呃、完备的还是soundy,同样也值得商榷。这篇博文描述的是我对这些术语定义的理解,以及关于它们在刻画一次静态分析是否有用的一些思考。在理解这些术语的过程中得到的一个有趣的结论就是:我们需要一套良好的基准测试套件来评估静态分析;我的感受则是,目前为止,我们有一些好的选项。
静态分析中的可靠性(soundness)
术语“可靠性(Soundness)”来自于形式逻辑和数理逻辑。在这些学科中,有所谓的“证明系统(proof system)”和“模型(model)”。证明系统由一系列的规则组成,人们可以用它来证明有关模型的“性质(properties)”(也被称作语句(statements))——这是某种数学结构,比如说某个定义域上的集合。如果一个证明系统 $L$ 所能证明的语句在该模型中确实为真,那么它就是可靠的。如果关于模型为真的任意语句,都能被 $L$ 所证明,那么它就是完备的(complete)。大多数有用的(interesting)证明系统不可能既可靠又完备:要么 $L$ 无法证明一些语义为真的语句,要么 $L$ 会证明一些语义为假的语句。
我们可以把静态分析看做是一种证明系统,用来证明某种性质对于一个程序的所有执行都成立;而程序(即它的所有可能的执行过程)充当了模型的角色。例如,静态分析器 Astrée 旨在证成这样的性质 $R$ :程序不会因为除零、数组索引越界或者空指针解引用等问题而表现出运行时错误。如果当 Astrée 说性质 $R$ 对于某个程序成立,并且这个程序的执行也没有产生运行时错误,那么 Astrée 就是可靠的。如果 Astrée 声称该性质成立而实则不然时:比如程序的某一次执行就存在错误——它就是不可靠的(unsound)。我的理解就是,除非附带一些假设,Astrée 不是可靠的;下面会详细阐述。
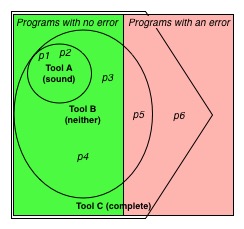
上图直观地展示了这种情况。方块的左边部分表示那些性质 $R$ 都成立的程序,即它们从不产生运行时错误。而右边的部分代表了那些对于性质 $R$ 不成立的程序,也就是那些有时会产生运行时错误的程序。左上角圆圈中的程序,分析器 $A
$ 判定它们满足性质 $R$ (包括了程序p1和p2 );$A$ 没有证明其它程序(包括了程序p3-p6)满足该性质。由于这个圆圈完全在方框的左半部分,$A$ 是可靠的:它绝不会把有错误的程序说成无错的。
假警报和完备性
静态分析通常通过“分析 $P$ 时不会发出警报”来声明程序 $P$ 具有性质 $R$。对于我们的例子来说,分析器 $A$ 在分析它所包含的圆圈里的程序时(比如p1和p2)不会产生警报,而对于圆圈外面的那些程序则会产生一些警报。而对于图片中那些在方框左半部分而又不在 $A$ 的圆圈里的那些程序(比如p3和p4),分析器 $A$ 产生的警报则是“假警报”,因为 $A$ 认为它们又运行时错误,但实则不然。
假警报在实践中确实存在,也是这些工具的用户的沮丧之源。大多数工具设计者尝试通过(某种方法)将他们的工具变成不可靠的来减少假警报。在我们的图示中,工具 $B$ 就是不可靠的:它的一部分圆圈所包含的程序(比如p5)就在方框的右半部分。
在极端情况下,工具可以在完全确定警报为真时才发出警报。这类工具的一个实例就是像 KLEE 这样的符号执行器:它找到的每一个错误都附带有一个输入,用来演示期望的性质是如何被违背的。在文献中,这类决不会产生假警报的工具有时候被称为“完备的”。回到证明理论,如果工具在分析程序时不产生警报,那么就是在声称目标程序具有期望的性质。因此,完备的工具不得对任何有效程序产生警报,即它必须没有假警报。
回到我们的示意图中,我们可以发现工具 $C$ 是完备的:它的五边形既完全包含了方块的左半部分,又涵盖了一些右半部分。这意味着所有具有性质 $R$ 正确程序都能够被他证明,但同样也会“证明”(根据分析时不会产生警报)一些具有运行时错误的程序。
Soundiness
术语“可靠的”和“完全的”的问题在于:它们本身的意义并不重要。对所有的程序都产生警报的分析器显然是可靠的。而接受所有程序的分析器(即不产生任何警报)的分析器显然也是“完全的”。理想的情况是,分析器应该力求保证既正确又完备,尽管想要做到这么完美通常是不可能的。分析器能达到的最好程度是怎样呢?二元的可靠性/完备性性质并不能告诉我们。
有一份提议通过另一种叫做“soundiness”的性质来解决这个问题。对于使用某些特定的编程范式或语言功能的程序,一个 Soundy 的工具并不能正确地分析出它们,但是对于那些没有使用这些功能的程序,工具的分析结果则是可靠的(而且几乎没有误报)。举例来说,如果选择忽视分析反射——因为“正确地”处理反射可能会产生很多假警报或者带来性能问题——那么很多 Java 分析工具都是 soundy 的。
这种 “soundiness” 的想法很吸引人,因为它能够找出那些旨在注重正确性的分析器,而不是将它们和一些不那么复杂的工具一起标记为“不正确的”。一些人批评 soundiness 这个概念没有什么“内在意义”。它基本上是在表示“在某种假设下算是正确的”。但是不同的工具又会做出不同的假设。这就导致了两个soundy的工具(很可能)无法相互比较。另一方面,我们可以有效地比较两种可靠的工具的有效性。
我们不应该(仅仅)声明一个工具是 soundy,而是应该声明它符合某些假设,并列出这些假设是什么。我的理解是:Astrée 在各种假设下都是正确,例如,目标程序不使用动态内存分配。(备注:当然还有其他的假设,包括程序不含有错误恢复后处理。参见下面 Xavier Rival 的评论)
精确度和召回率
不在绝对意义上去证明有效性,而在一定假设的前提下证明有效性,仍然不能完全解决问题。我们需要一种方法来衡量(reasoning)一种工具的效用(utility)。它应该证明大多数正确的程序,但只混入很少错误程序,并且只发出些许假警报。用来报告工具效用的量化方法就是使用“精确度和召回率”。在工具所作出的判断中,前者(精确度)衡量的是有多少是正确的,而后者(召回率)衡量的是其中正确判断占所有可能正确的判断的比例。
这里是这些术语的定义。假设我们有 $N$ 个程序,以及一个静态分析器,使得:
- $N$ 个程序中的 $X$ 个具有非平凡的性质(例如性质 $R$,没有运行时错误);
- 剩余的 $N-X$ 个程序不具备这样的性质;
- 这 $X$ 个具有性质 $R$ 的程序中,有 $T$ 个程序($T \le X$ )被静态分析器所证明,即,分析器正确地没有产生警报;
- 而剩余的 $N-X$ 个违背性质 $R$ 的程序中,有 $F$ 个程序( $F \le N-X$ ) 被静态分析器“不正确地”证明了,即,分析器“不正确地”沉默了。
那么,静态分析器的精确率就是 $T/(T+F)$,而它的召回率就是 $T/X$。
一个正确的静态分析器应该具有完美的精确率(也就是1),因为对于这些分析器来说,我们总是有$F=0$。一个完全的静态分析器总是具有完美的召回率,因为 $T=X$。实际分析器介于两者之间; 理想的是精确度和召回率都接近1。
回想一下我们的图示。我们可以计算三种工具分析程序p1-p6的精确度和召回率。本例中,$N=6$、$X=4$。
- 对于工具 $A$ 来说,参数 $T=2$(分别是
p1和p2)、$F=0$,这样精确度$=1$而召回率为 $1/2$; - 对于工具 $B$ 来说,参数 $T=4$(分别是
p1-p4)、$F=1$(即程序p5),因此它的精确度 $=4/5$而召回率 $=1$; - 最后,工具 $C$ 的参数为 $T=4$、$F=2$(即程序
p5和p6),因此它的精确度$=2/3$而召回率$=1$。
精确度和召回率的局限
尽管准确度和召回率弥合了正确性和完备性在实践中的鸿沟,但它们也有自身的问题。问题之一就是这些计量本质上是经验性的,而不是概念性的。最好的情况是,我们可以计算某些程序的精确度和召回率,即基准套件中的程序(如我们示意图中的p1-p6),并希望这些计量能够推广到所有程序。另一个问题是,可能很难知道所考虑的程序是否会表现出感兴趣的性质; 也就是说,我们可能缺乏基本事实。
另一个问题是精确度和召回率是为整个程序定义的。但实际的程序足够庞大和复杂,即使是精心设计的工具也会发出一些警报来错误地对大多数工具进行归类。因此,我们可以尝试专注于程序错误,而不是专注于整个程序。例如,对于旨在证明数组索引在边界内的工具,我们可以计算程序中的数组索引表达式的数量($N$),没有越界的数量($X$)以及工具通过不发出警报正确接受的数量($T$),以及因为未发出警报而接受错误的数量($F$)。通过这种计算,Astrée 将非常好地堆积:它在 125,000 行程序中(其中可能有很多出现的数组索引,指针取消引用等)只发出三个假警报。
该定义仍然显示出我们需要知道基本事实(即哪些程序属于 $X$)的问题,这对于某些类型的错误(例如,数据争用)可能是非常困难的。 也许很难想出一种计算潜在错误的方法。 例如,对于数据争用,我们必须考虑涉及到一个读和一个写的(所有)可行的线程/程序点组合。计量 BUG 个数的问题提出了一个哲学问题,即“怎样才算是一个 BUG”-如何将一个错误与另一个错误分开?定义整个程序的精确度/召回率是需要计算的。
结论
可靠性和完备性定义了静态分析有效性的边界。一个完美的工具两者都会实现。但是完美通常是不可能的,实际中,仅仅满足只是正确或完备就很少。精确度和召回率提供了一种量化的方式,但是它们的计算都正对一套特定的基准测试套件,并且需要知道基本事实。在很多情况下,基准测试套件的普适性(generalizability)是未经证实的,更无法确定基本事实。
因此,似乎实践中评估静态分析最有用的方法可能是制通用性陈述-例如适用于所有程序的可靠性或完备性(在某种假设下)-以及适用于某些程序的经验性陈述,甚至还可以带有不确定性。这两种陈述都提供了实用性和普遍性的证据。
为了做到这一点,我们需要基准套件,我们拥有可普遍性和(至少某种程度的)基本事实的独立证据。 我的印象是,对于静态分析问题,确实没有好的选择。 我建议这是一个值得进一步研究的紧迫问题!
Xavier Rival的评论
(Xavier Rival 是 Astrée 的参与者一直,这里只选取了评论的部分内容)
其中一个原因就是,对程序的所有执行来说,当语言中存在未定义的行为时,非常难以说清楚某事是有意义的。其中一个例子就是C程序破坏了内存安全。那么,一个简单的语句*p = e;就会导致程序崩溃(然后执行就停止了——在程序分析的结果中很容易捕获到),或者程序会有各种各样的行为,包括写入内存其他位置,腐坏(corrupting)代码等等。因此,如果我们考虑的静态分析器旨在发现所有可能的运行时错误以及未定义行为,那么在操作*p = e;被报告为“不安全”之后,通常很难去定义一个正确又精确的分析状态。一种好的解决方案就是让分析器在此时发出警报,并明确执行分析语义,即*p = e; 写入未指定位置的执行被切断了(CUT),并且分析仅在正确执行时继续。在这种情况下,Astrée 实际上会这样做。对于上面的可靠性定义,这是完全正确的,因为写入未定义位置的执行将不会出现在 Exec' 中。
例如,让我们考虑:
y = 0;
t[-1] = 1;
x = y;
实际执行时可能会崩溃,或者会将 1 写入到 t 的内存空间之前,因此如果该空间是 y,那么x = y 实际上会把 1 储存在 x 中;考虑到像这样的未定义行为非常难以定义之后可能发生的所有事情,并且与用户不太相关(这里应该只考虑修复数组访问),因此 Astrée 将发出与数组访问相关的警报, 并切断跟踪。
……
总结一下,我认为对于终端用户来说,理解关于可靠性陈述的假设非常重要,以便1) 找出他们需要提供给工具的假设,以及2)准确地知道分析器的结果表示什么。